solr 基本介绍
Apache Solr (读音: SOLer) 是一个开源的搜索服务器。Solr 使用 Java 语言开发,主要基于 HTTP 和 Apache Lucene 实现。Apache Solr 中存储的资源是以 Document 为对象进行存储的。每个文档由一系列的 Field 构成,每个 Field 表示资源的一个属性。Solr 中的每个 Document 需要有能唯一标识其自身的属性,默认情况下这个属性的名字是 id,在 Schema 配置文件中使用:id进行描述。 Solr是一个高性能,采用Java开发,基于Lucene的全文搜索服务器。文档通过Http利用XML加到一个搜索集合中。查询该集合也是通过 http收到一个XML/JSON响应来实现。它的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,高亮显示搜索结果,通过索引复制来提高可用性,提 供一套强大Data Schema来定义字段,类型和设置文本分析,提供基于Web的管理界面等。
solr 名称来源
Search On Lucene Replication
solr 历史
2004年 CNET 开发 Solar,为 CNET 提供站内搜索服务 2006年1月捐献给 Apache ,成为 Apache 的孵化项目 一年后 Solr 孵化成熟,发布了1.2版,并成为 Lucene 的子项目 2010年6月,solr 发布了的1.4.1版,这是1.4的 bugfix 版本,1.4.1的solr使用的lucene是2.9版本的 solr 从1.4.x版本以后,为了保持和lucene同步的版本,solr直接进入3.0版本。
环境准备
 http://mirrors.hust.edu.cn/apache/lucene/solr/
http://mirrors.hust.edu.cn/apache/lucene/solr/
-
下载Tomcat 8或者 Tomcat 9 并解压 可以直接在Tomcat官方网站进行下载安装。 https://tomcat.apache.org/download-90.cgi
部署Solr到Tomcat
说明: 我的解压路径
#Solr:D:\develop\solr-7.3.0
#Tomcat:D:\webserver\apache-tomcat-9.0.1
复制Solr文件到Tomcat
- 拷贝文件夹
D:\develop\solr-7.3.0\server\solr-webapp\webapp 到
D:\webserver\apache-tomcat-9.0.1\webapps\ 下,并且重命名为
solr7.3 - 复制D:\develop\solr-7.3.0\server\lib\ext 下的所有Jar包到 D:\webserver\apache-tomcat-9.0.1\webapps\solr7.3\WEB-INF\lib
- 复制D:\develop\solr-7.3.0\dist下的
solr-dataimporthandler-7.3.0.jarsolr-dataimporthandler-extras-7.3.0.jar
到D:\webserver\apache-tomcat-9.0.1\webapps\solr7.3\WEB-INF\lib - 复制D:\develop\solr-7.3.0\server\lib下的
metrics-开头的五个Jar 到D:\webserver\apache-tomcat-9.0.1\webapps\solr7.3\WEB-INF\lib - 复制D:\develop\solr-7.3.0\server\resources\log4j.properties到 D:\webserver\apache-tomcat-9.0.1\webapps\solr7.3\WEB-INF\classes
配置Solr Home
- 新建文件夹D:\develop\solr-7.3.0-home,复制D:\develop\solr-7.3.0\server\solr下的所有内容到D:\develop\solr-7.3.0-home。
- 打开D:\webserver\apache-tomcat-9.0.1\webapps\solr7.3\WEB-INF\web.xml 在47行配置SolrHome,用于指定数据存放位置。
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>D:\develop\solr-7.3.0-home</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
关闭安全约束
注释掉D:\webserver\apache-tomcat-9.0.1\webapps\solr7.3\WEB-INF\web.xml最下方的安全约束,让项目启动之后可以正常访问。
<!-- Get rid of error message -->
<!--
<security-constraint>
<web-resource-collection>
<web-resource-name>Disable TRACE</web-resource-name>
<url-pattern>/</url-pattern>
<http-method>TRACE</http-method>
</web-resource-collection>
<auth-constraint/>
</security-constraint>
<security-constraint>
<web-resource-collection>
<web-resource-name>Enable everything but TRACE</web-resource-name>
<url-pattern>/</url-pattern>
<http-method-omission>TRACE</http-method-omission>
</web-resource-collection>
</security-constraint>
-->
Tomcat启动访问
至此,Solr配置以及完成,启动Tomcat访问 http://localhost:8080/solr7.3/index.html
 )
)
创建Solr Core
点击网页左侧菜单Core Admin
输入
name:blog
instanceDir:blog
点击Add Core,网页上方提示在D:\develop\solr-7.3.0-home\blog下无法找到solrconfig.xml:
Error CREATEing SolrCore 'blog': Unable to create core [blog] Caused by: Can't find resource 'solrconfig.xml' in classpath or 'D:\develop\solr-7.3.0-home\blog'
我们复制官方给出的默认配置,复制
D:\develop\solr-7.3.0-home\configsets_default\conf
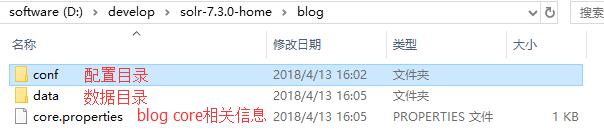
到D:\develop\solr-7.3.0-home\blog下,回到页面,再次点击Add Core,等待页面添加成功自动刷新。
此时,在SolrHome下的blog文件夹下生成了相关文件:
添加 Core 字段
在页面上添加
打开http://localhost:8080/solr7.3/index.html选择左侧菜单Core Selector 选择刚才添加的blog,接着选择下面的Schema。可以在出现的页面上填写字段信息name:title,field type:string,然后点击Add Field完成添加。
Solr中的Field、CopyField、DynamicField与其他Field
在配置文件中添加
我们打开文件: D:\develop\solr-7.3.0-home\blog\conf\managed-schema 搜索title关键词,搜索到如下信息:
<field name="title" type="string" indexed="true" stored="true"/>
可见,我们刚才在页面添加的字段信息最终会生成此条配置,因此,我们也可以拷贝这个配置更改name值为content就可以完成content字段的添加。
配置完成之后点击页面Core Admin 然后点击Reload刷新信息,我们就可以在Schema中查看到content字段。
添加/更新/查询数据
在页面选择blog Core,选择Documents,在Document(s)中输入下面内容进行数据然后点击Submit Document添加数据,如果ID已经存在,则为更新。如果JSON中没有写ID字段,会随机生成ID。
{
"id": "10000",
"title": "Sorl入门教程",
"content": "sorl下载,solr配置,solr启动"
}
提交之后可以看到成功添加信息的反馈。
Status: success
Response:
{
"responseHeader": {
"status": 0,
"QTime": 4
}
}
数据已经成功添加,如果需要查询数据可以点击左侧Query,点击Execute Query查询出刚才添加的数据。
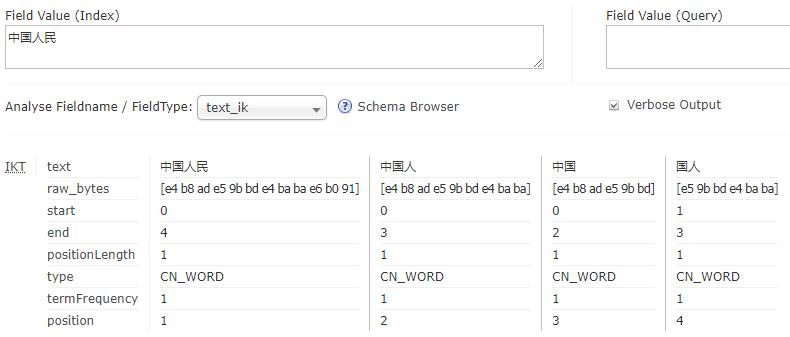
中文分词器的使用
在已经运行的页面上,选择blog Core,然后选择Analysis,输入中国人民,字段类型选择_text_,点击Analyse Values可以看到没有中文分词器的结果:
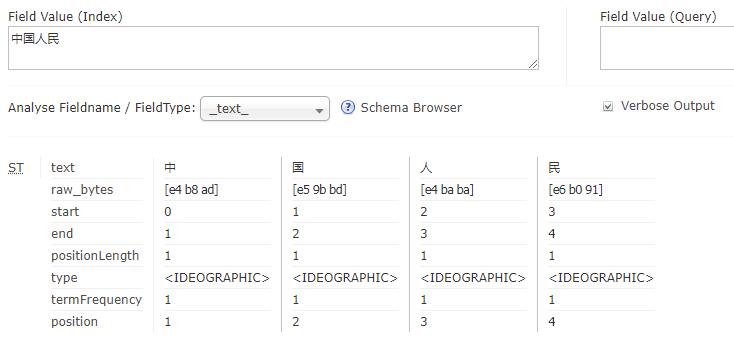
下面使用中文分词器,下载ikanalyzer-solr6.5
解压将IKAnalyzer.cfg.xml以及stopword.dic解压到
\apache-tomcat-9.0.1\webapps\solr7.3\WEB-INF\classes
解压将里面的两个jar包ik-analyzer-solr5-5.x.jar以及solr-analyzer-ik-5.1.0.jar解压到
\apache-tomcat-9.0.1\webapps\solr7.3\WEB-INF\lib
打开刚才创建的blog core目录\solr-7.3.0-home\blog\conf,编辑managed-schema文件添加配置:
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
在页面选择Core Admin -> blog -> Reload 刷新配置,然后选择blog Core,然后选择Analysis,输入中国人民,字段类型选择text_ik,点击Analyse Values可以看到没有中文分词器的结果: