Java 集合框架是 Java 语言中提供的一个重要工具库,可以用于存储和处理数据集合。集合框架提供了一组通用接口和类,用于表示不同特性的集合,如列表 List、集合、队列 Queue 和映射 Map 等。 集合框架由接口、实现类及其相应的算法和数据结构进行实现,是 JDK 中非常重要且常用的类库,每一个 Java 程序员都应该充分掌握。
下面是 Java 集合框架的关系依赖图:
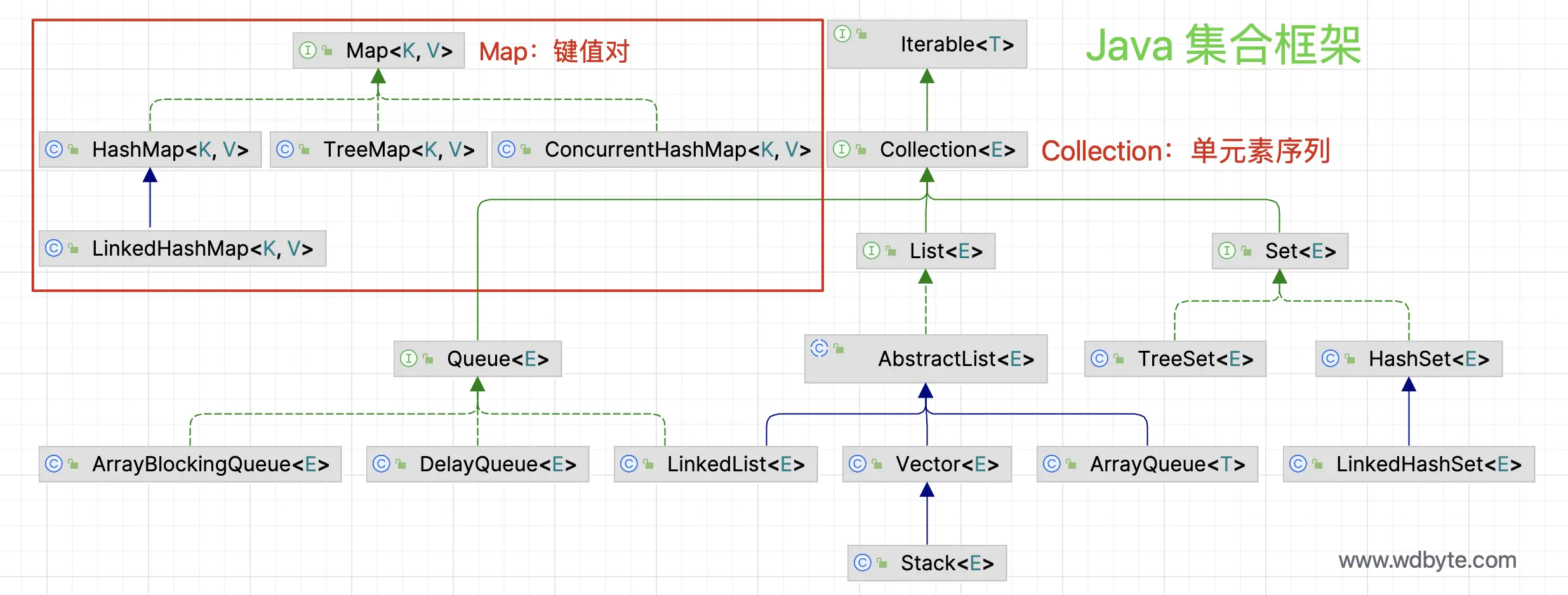
从图中可以发到 Java 中的集合框架主要是 Collection 和 Map,两者是根据存放的内容形式不同来区分的,Collection 主要存储单元素序列,而 Map 主要用来存储键值对关系。
Collection
Collection 接口是所有单元素序列集合的上层接口,定义了所有单元素序列集合共有的基本操作,如添加、删除和遍历等。其中 List 接口是有序集合,允许存储重复元素,Set 接口是无序集合,不允许重复元素,Queue 接口具有队列常见操作方法。
Collection 接口常用方法说明:
| 方法名 | 描述 |
|---|---|
| add(E e) | 将元素添加到集合中 |
| remove(Object o) | 删除集合中指定元素 |
| clear() | 删除集合中所有元素 |
| size() | 返回集合中元素的数量 |
| isEmpty() | 判断集合是否为空 |
| contains(Object o) | 判断集合是否包含指定元素 |
| toArray() | 将集合转化为数组 |
| iterator() | 返回集合的迭代器 |
| addAll(Collection<? extends E> c) | 将另一个集合中的元素添加到当前集合中 |
| removeAll(Collection<?> c) | 删除当前集合中与另一个集合中相同的元素 |
| retainAll(Collection<?> c) | 保留当前集合中与另一个集合中相同的元素,删除其他元素 |
| containsAll(Collection<?> c) | 判断当前集合是否包含另一个集合中的所有元素 |
比如 ArrayList 和 LinkedList 都实现了 List 接口,说明它们可以存储单元素序列,只是两者分别基于数组及链表实现;HashSet 和 LinkedHashSet 实现了 Set 接口,分别基于散列表和链表实现。TreeSet 实现了 SortedSet 接口,基于红黑树实现;
ArrayList 使用示例:
package com.wdbyte.collection;
import java.util.ArrayList;
import java.util.List;
/**
* @author https://www.wdbyte.com
*/
public class CollectionTest {
public static void main(String[] args) {
List<String> arrayList = new ArrayList<>();
// 向 List 中添加元素
arrayList.add("www");
arrayList.add("wdbyte");
arrayList.add("com");
arrayList.add("com");
// 输出
System.out.println(arrayList);
}
}
输出:[www, wdbyte, com, com]
Map
Map 是键值对集合,它允许重复值但不允许重复键。在 Map 中,可以使用键来查找值。Map 把键值关系进行绑定,因此有时候也被成为字典。Map 集合是非常强大且常用的编程工具,在 Java 中使用最多的是 HashMap。
Map 常用方法说明:
| 方法名 | 描述 |
|---|---|
| clear() | 删除 Map 中的所有映射关系 |
| containsKey(Object key) | 判断 Map 中是否包含指定的 key |
| containsValue(Object value) | 判断 Map 中是否包含指定的 value |
| get(Object key) | 返回与指定 key 关联的 value,如果 Map 不包含该 key,则返回 null |
| isEmpty() | 判断 Map 是否为空 |
| put(K key, V value) | 在 Map 中添加一个映射关系,如果 Map 中已经存在该 key,则替换原有的 value |
| putAll(Map<? extends K, ? extends V> m) | 将指定 Map 中的所有映射复制到当前 Map 中 |
| remove(Object key) | 从 Map 中删除指定的 key 及其对应的 value |
| size() | 返回 Map 中的映射数量 |
| entrySet() | 返回 Map 中包含的映射关系的 Set 视图 |
| keySet() | 返回 Map 中包含的所有 key 的 Set 视图 |
| values() | 返回 Map 中包含的所有 value 的 Collection 视图 |
void forEach(BiConsumer<? super K,? super V> action) |
遍历 Map 中的每个元素,并执行给定的操作 |
V getOrDefault(Object key, V defaultValue) |
如果 Map 中包含指定的 key,则返回其对应的 value,否则返回 defaultValue |
V putIfAbsent(K key, V value) |
如果该 key 在 Map 中不存在,则将 key 和 value 关联起来,并返回 null,否则返回已有的 value |
boolean remove(Object key, Object value) |
如果指定的 key 在 Map 中存在,并且其对应的 value 与给定的 value 相同,则删除该映射关系 |
V replace(K key, V value) |
如果指定的 key 在 Map 中存在,则将其对应的 value 替换为给定的 value,并返回原有的 value,否则返回 null |
boolean replace(K key, V oldValue, V newValue) |
如果指定的 key 在 Map 中存在,并且其对应的 value 为 oldValue,则将其替换为 newValue,并返回 true,否则返回 false |
void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) |
遍历 Map 中的每个元素,并将其 value 替换为给定的函数返回的新 value |
需要注意的是,上述方法中的 BiConsumer、BiFunction 是 Java 8 中新增的函数式接口。
HashMap 使用实例:
package com.wdbyte.collection;
import java.util.HashMap;
import java.util.Map;
/**
* @author https://www.wdbyte.com
*/
public class MapTest {
public static void main(String[] args) {
Map<String, String> hashMap = new HashMap<>();
// 添加元素
hashMap.put("site","www.wdbyte.com");
hashMap.put("author","程序猿阿朗");
hashMap.put("github","github.com/niumoo");
// 获取元素
System.out.println(hashMap.get("github"));
// 输出全部元素
System.out.println(hashMap);
}
}
输出:
github.com/niumoo
{site=www.wdbyte.com, github=github.com/niumoo, author=程序猿阿朗}
添加元素 & 打印集合
对于 Collection 和 Map , JDK 中实现的集合都已经重写了 toString() 方法,用于方便输出集合中的内容,对于添加元素,Collection 添加元素使用 add 方法,Map 集合添加元素使用 put 方法。
package com.wdbyte.collection;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.LinkedList;
import java.util.List;
import java.util.Set;
import java.util.Stack;
import java.util.TreeSet;
/**
* @author https://www.wdbyte.com
*/
public class CollectionTest2 {
public static void main(String[] args) {
List<String> arrayList = new ArrayList<>();
List<String> linkedList = new LinkedList<>();
Set<String> hashSet = new HashSet<>();
Set<String> treeSet = new TreeSet<>();
Stack<String> stack = new Stack<>();
// 添加元素
arrayList.add("wdbyte.com");
linkedList.add("wdbyte.com");
hashSet.add("wdbyte.com");
treeSet.add("wdbyte.com");
stack.add("wdbyte.com");
// 输出
System.out.println(arrayList);
System.out.println(linkedList);
System.out.println(hashSet);
System.out.println(treeSet);
System.out.println(stack);
}
}
输出:
[wdbyte.com]
[wdbyte.com]
[wdbyte.com]
[wdbyte.com]
[wdbyte.com]
Map 集合添加和输出集合测试:
package com.wdbyte.collection;
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.Map;
/**
* @author https://www.wdbyte.com
*/
public class MapTest2 {
public static void main(String[] args) {
Map<String, String> hashMap = new HashMap<>();
Map<String, String> linkedHashMap = new LinkedHashMap<>();
// 添加元素
hashMap.put("site", "www.wdbyte.com");
hashMap.put("author", "程序猿阿朗");
hashMap.put("github", "github.com/niumoo");
linkedHashMap.put("site", "www.wdbyte.com");
linkedHashMap.put("author", "程序猿阿朗");
linkedHashMap.put("github", "github.com/niumoo");
// 输出全部元素
System.out.println(hashMap);
System.out.println(linkedHashMap);
}
}
输出中可以发现 LinkedHashMap 可以保证元素插入的顺序。
{site=www.wdbyte.com, github=github.com/niumoo, author=程序猿阿朗}
{site=www.wdbyte.com, author=程序猿阿朗, github=github.com/niumoo}
迭代器 Iterator
在上面 Collection 接口的方法介绍中,有一个 iterator() 方法,它可以返回集合的迭代器。**为什么会有迭代器这个东西?**它是做什么用的呢?没有这个迭代器会怎么样呢?
Collection 集合最常见的操作应该是 add 放入一个元素,get 取出一个元素,遍历元素。但是如果针对 List 编写了一个功能,比如遍历所有元素进行输出,输出时在内容前拼接当前日期。后面我们突然发现用 Set 集合更加合理,那么我们针对 List 编写的方法是不是都要进行改造呢?又或者我们就是要编写一些通用的集合功能,并不关心集合的类型,该如何编写呢?
迭代器解决了这个问题,它提供了访问集合的一种新的方式,让我们可以不关心集合类型,不关心集合大小。在 Java 集合中,使用 iterator() 方法创建当前集合的迭代器。
迭代器中有几个常用的方法:
- hasNext():判断是否还有下一个元素,如果有返回 true,否则返回 false。
- next():返回下一个元素。
- remove():删除迭代器最近返回的元素。
示例:遍历所有元素进行输出,输出时在内容前拼接当前日期。
package com.wdbyte.collection;
import java.time.LocalDate;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
/**
* @author https://www.wdbyte.com
*/
public class CollectionTest4 {
public static void main(String[] args) {
List<String> arrayList = new ArrayList<>();
// 向 List 中添加元素
arrayList.add("www");
arrayList.add("wdbyte");
arrayList.add("com");
HashSet<String> hashSet = new HashSet<>();
hashSet.addAll(arrayList);
printCollection(arrayList.iterator());
System.out.println("--------------");
printCollection(hashSet.iterator());
}
public static void printCollection(Iterator<String> iterator) {
// 当前日期
LocalDate now = LocalDate.now();
while (iterator.hasNext()) {
String obj = iterator.next();
System.out.println(now + ":" + obj.toString());
}
}
}
输出;
2023-05-03:www
2023-05-03:wdbyte
2023-05-03:com
--------------
2023-05-03:com
2023-05-03:wdbyte
2023-05-03:www
因为迭代器是一个接口,所以也可以直接使用迭代器接口作为入参:
public static void main(String[] args) {
List<String> arrayList = new ArrayList<>();
// 向 List 中添加元素
arrayList.add("www");
arrayList.add("wdbyte");
arrayList.add("com");
HashSet<String> hashSet = new HashSet<>();
hashSet.addAll(arrayList);
printCollection(arrayList);
printCollection(hashSet);
}
public static void printCollection(Iterable<String> iterable) {
// 当前日期
LocalDate now = LocalDate.now();
Iterator<String> iterator = iterable.iterator();
while (iterator.hasNext()) {
String obj = iterator.next();
System.out.println(now + ":" + obj.toString());
}
}
由此可见,迭代器是一种很实用的设计模式,它可以获取一个迭代对象,对指定数据集合进行迭代。
类型推断
从 Java 10 开始,增加了 var 关键词定义类型的方式,Java 将会自动进行类型推断,这样可以减少代码量,但是也会降低代码的可读性。
var hashMap = new HashMap<String, String>();
hashMap.put("公众号","程序猿阿朗");
var string = "hello java 10";
var stream = Stream.of(1, 2, 3, 4);
var list = new ArrayList<String>();
相关文章:JEP 286 - 局部类型推断
总结
Java 集合中使用最多的是 ArrayList、HashSet、HashMap,作为 Java 开发者应该充分掌握。Java 集合框架的优点在于其方便性、高效性、通用性和可扩展性。Java 集合框架提供了许多高效的数据结构和算法,能够满足不同的应用需求。此外,集合框架的通用性使得其可以适用于各种不同的应用场景,而集合框架的可扩展性则使得其能够方便地扩展和定制以满足特殊需求。
一如既往,文章中代码存放在 Github.com/niumoo/javaNotes.