感谢看客老爷点进来了,周末闲来无事,想起同事强哥的那句话:“你有没有玩过断点续传?” 当时转念一想,断点续传下载用的确实不少,具体细节嘛,真的没有去思考过啊。这不,思考过后有了这篇文章。感谢强哥,让我有了一篇可以水的文章,下面会用纯 Java 无依赖实现一个简单的多线程断点续传下载器。
这篇水文章到底有什么内容呢?先简单列举一下,顺便思考几个问题。
- 断点续传的原理。
- 重启续传文件时,怎么保证文件的一致性?
- 同一个文件多线程下载如何实现?
- 网速带宽固定,为什么多线程下载可以提速?
多线程断点续传会用到哪些知识呢?上面已经抛出了几个问题,不放思考一下。下面会针对上面的四个问题一一进行解释,现在大多数的服务都可以在线提供,下载使用的场景越来越少,不过这不妨碍我们对原理的探求。
断点续传的原理
想要了解断点续传是如何实现的,那么肯定是要了解一下 HTTP 协议了。HTTP 协议是互联网上应用最广泛网络传输协议之一,它基于 TCP/IP 通信协议来传递数据。所以断点续传的奥秘也就隐藏在这 HTTP 协议中了。
我们都知道 HTTP 请求会有一个 Request header 和 Response header ,就在这请求头和响应头里,有一个和 Range 相关的参数。下面通过百度网盘的 pc 客户端下载链接进行测试。
使用 cURL 查看 response header. 如果你想知道更多关于 cURL 的用法,可以看我之前的一篇文章 :进来领略下cURL的独门绝技。
$ curl -I http://wppkg.baidupcs.com/issue/netdisk/yunguanjia/BaiduYunGuanjia_7.0.1.1.exe
HTTP/1.1 200 OK
Server: JSP3/2.0.14
Date: Sat, 25 Jul 2020 13:41:55 GMT
Content-Type: application/x-msdownload
Content-Length: 65804256
Connection: keep-alive
ETag: dcd0bfef7d90dbb3de50a26b875143fc
Last-Modified: Tue, 07 Jul 2020 13:19:46 GMT
Expires: Sat, 25 Jul 2020 14:05:19 GMT
Age: 257796
Accept-Ranges: bytes
Cache-Control: max-age=259200
Content-Disposition: attachment;filename="BaiduYunGuanjia_7.0.1.1.exe"
x-bs-client-ip: MTgwLjc2LjIyLjU0
x-bs-file-size: 65804256
x-bs-request-id: MTAuMTM0LjM0LjU2Ojg2NDM6NDM4MTUzMTE4NTU3ODc5MTIxNzoyMDIwLTA3LTA3IDIyOjAxOjE1
x-bs-meta-crc32: 3545941535
Content-MD5: dcd0bfef7d90dbb3de50a26b875143fc
superfile: 2
Ohc-Response-Time: 1 0 0 0 0 0
Access-Control-Allow-Origin: *
Access-Control-Allow-Methods: GET, PUT, POST, DELETE, OPTIONS, HEAD
Ohc-Cache-HIT: bj2pbs54 [2], bjbgpcache54 [4]
可以看到百度 pc 客户端的 response header 信息有很多,我们只需要重点关注几个。
Content-Length: 65804256 // 请求的文件的大小,单位 byte
Accept-Ranges: bytes // 是否允许指定传输范围,bytes:范围请求的单位是 bytes (字节),none:不支持任何范围请求单位,
Last-Modified: Tue, 07 Jul 2020 13:19:46 GMT // 服务端文件最后修改时间,可以用于校验文件是否更改过
x-bs-meta-crc32: 3545941535 // crc32,可以用于校验文件是否更改过
ETag: dcd0bfef7d90dbb3de50a26b875143fc //Etag 标签,可以用于校验文件是否更改过
可见并不见得所有下载都支持断点续传,只有在 response header 中有 Accept-Ranges: bytes 字段时才可以断点续传。如果有这个信息,该怎么断点续传呢?其实只需要在 response header 中指定 Content-Range 值就可以了。
Content-Range 使用格式有下面几种。
Content-Range: <unit>=<range-start>-<range-end>/<size> // size 为文件总大小,如果不知道可以用 *
Content-Range: <unit>=<range-start>-<range-end>/*
Content-Range: <unit>=<range-start>-
Content-Range: <unit>=*/<size>
举例:
单位 bytes,从第 10 个 bytes 开始下载:Content-Range: bytes=10-.
单位 bytes,从第 10 个 bytes 开始下载,下载到第100个 bytes:Content-Range: bytes=10-100.
这就是断点续传实现的原理了,你可以能已经发现了,Content-Range 的 start 和 end 已经让分段下载有了可能。
怎么保证文件的一致性?
这里要说的文件完整性有两个方面,一个是下载阶段的,一个是写入阶段的。
因为我们要写的下载器是支持断点续传的,那么在进行续传时,怎么确定文件自从我们上次下载时没有进行过更新呢?其实可以通过 response header 中的几个属性值进行判断。
Last-Modified: Tue, 07 Jul 2020 13:19:46 GMT // 服务端文件最后修改时间,可以用于校验文件是否更改过
ETag: dcd0bfef7d90dbb3de50a26b875143fc //Etag 标签,可以用于校验文件是否更改过
x-bs-meta-crc32: 3545941535 // crc32,可以用于校验文件是否更改过
Last-Modified 和 ETag 都可以用来检验文件是否更新过,根据 HTTP 协议的规定,当文件更新时,是会生成新的 ETag 值的,它类似于文件的指纹信息,而 Last-Modified 只是上次修改时间,有时可能并不能够证明文件内容被修改过。
上面是下载阶段的文件一致性校验,那么在写入阶段呢?不管单线程还是多线程,由于要断点续传,在写入时都要在指定位置进行字符追加。在 Java 中有没有好的实现方式?
答案是一定的,使用 RandomAccessFile 类即可,RandomAccessFile 不同于其他的流操作。它可以在使用时指定读写模式,使用 seek 方法随意的移动要操作的文件指针位置。很适合断点续传的写入场景。
比如在 test.txt 的位置 0 开始写入字符 abc,在位置 100 开始写入字符 ddd.
try (RandomAccessFile rw = new RandomAccessFile("test.txt", "rw")){ // rw 为读写模式
rw.seek(0); // 移动文件内容指针位置
rw.writeChars("abc");
rw.seek(100);
rw.writeChars("ddd");
}
断点续传的写入就靠它了,在续传时只需要移动文件内容指针到要续传的位置即可。
seek 方法还有很多妙用,比如使用它你可以快速定位到已知的位置,进行快速检索;也可以在同一个文件的不同位置进行并发读写。
多线程下载如何实现?
多线程下载必然要每个线程下载文件中的一部分,然后把每个线程下载到的文件内容组装成一个完整的文件,在这个过程中肯定是一个 byte 都不能出错的,不然你组装起来的文件是肯定运行不起来的。那么怎么实现下载文件的一部分呢?其实在断点续传的部分已经介绍过了,还是 Content-Range 参数,只要计算好每个部分要下载的 bytes 范围就可以了。
比如:单位 bytes,第二部分从第 10 个 bytes 开始下载,下载到第100个 bytes:Content-Range: bytes=10-100.
网速带宽固定,为什么多线程下载可以提速?
这是一个比较有意思的问题了,最大网速是固定的,运营商给你 100Mbs 的网速,不管你怎么使用,速度最大也就是 100/8=12.5MB/S. 既然瓶颈在这里,为什么多线程下载可以提速呢?其实理论上来说,单线程下载就可以达到最大网速。但是往往事实是网络不是那么通畅,十分拥堵,很难达到理想的最大速度。也就是说只有在网络不那么通畅的时候,多线程下载才能提速。否则,单线程即可。不过最大速度永远都是网络带宽。
那为什么多线程下载可以提速呢?HTTP 协议在传输时候是基于 TCP 协议传输数据的,为了弄明白这个问题需要了解一下 TCP 协议的拥塞控制机制。拥塞控制 是TCP 的一个避免网络拥塞的算法,它是基于和性增长/乘性降低这样的控制方法来控制拥塞的。
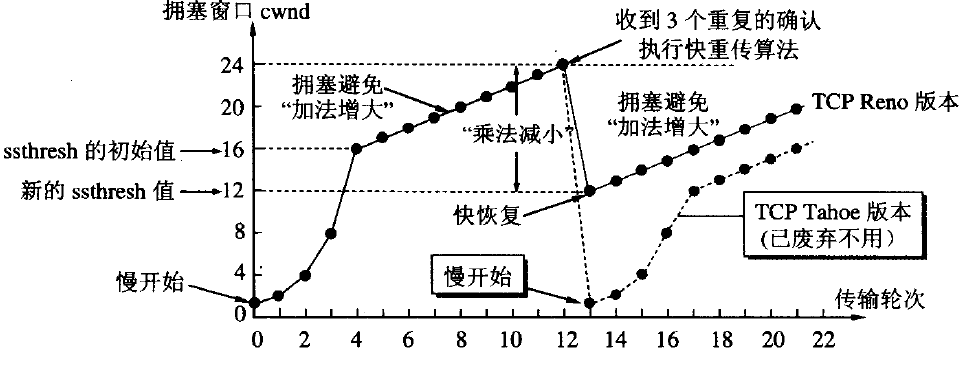
简单来说就是在 TCP 开始传输数据时,服务端会不断的探测可用带宽。在一个传输内容段被成功接收后,会加倍传输两倍段内容,如果再次被成功接收,就继续加倍,直到发生了丢包,这是这也被叫做慢启动。当达到**慢启动阀值(ssthresh)**时,满启动算法就会转换为线性增长的阶段,每次只增加一个分段,放缓增加速度。我觉得其实慢启动的加倍增速过程并不慢,只是一种叫法。
但是当发生了丢包,也就是检测到拥塞时,发送方就会将发送段大小降低一个乘数,比如二分之一,慢启动阈值降为超时前拥塞窗口的一半大小、拥塞窗口会降为1个MSS,并且重新回到慢启动阶段。这时多线程的优势就体现出来了,因为你的多线程会让这个速度减速没有那么猛烈,毕竟这时可能有另一个线程正处在慢启动的在最终加速阶段,这样总体的下载速度就优于单线程了。
多线程断点续传代码实现
基于上面的原理介绍,心里应该有了具体的实现思路了。我们只需要使用多线程,结合 Content-Range 参数分段请求文件内容保存到临时文件,下载完毕后使用 RandomAccessFile 把下载的文件合并成一个文件即可。而在需要断点续传时,只需要读取一下当前临时文件大小,然后调整 Content-Range ,就可以进行续传下载。
代码不多,下面是部分核心代码,完整代码可以直接点开文章最后的 Github 仓库。
Content-Range请求指定文件的区间内容。
URL httpUrl = new URL(url);
HttpURLConnection httpConnection = (HttpURLConnection)httpUrl.openConnection();
httpConnection.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36");
httpConnection.setRequestProperty("RANGE", "bytes=" + start + "-" + end + "/*");
InputStream inputStream = httpConnection.getInputStream();
- 获取文件的 ETag.
Map<String, List<String>> headerFields = httpConnection.getHeaderFields();
List<String> eTagList = headerFields.get("ETag");
System.out.println(eTagList.get(0));
- 使用
RandomAccessFile续传写入文件。
RandomAccessFile oSavedFile = new RandomAccessFile(httpFileName, "rw");
oSavedFile.seek(localFileContentLength); // 文件写入开始位置指针移动到已经下载位置
byte[] buffer = new byte[1024 * 10];
int len = -1;
while ((len = inputStream.read(buffer)) != -1) {
oSavedFile.write(buffer, 0, len);
}
断点续传测试,下载一部分之后关闭程序再次启动。
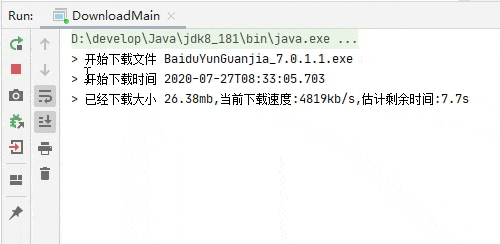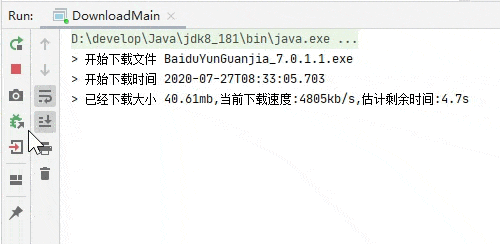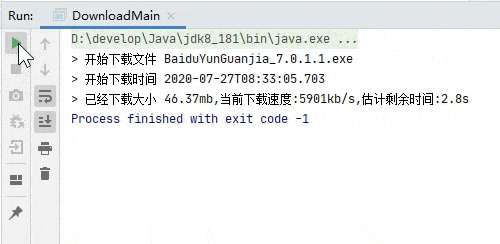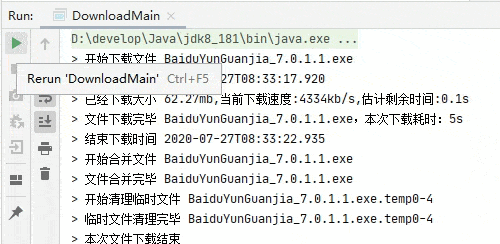
完整代码已经上传到 github.com/niumoo/down-bit.
参考:
[1] HTTP headers
[4] 维基百科 - TCP拥塞控制
[5] 维基百科 - 和性增长/乘性降低
最后的话
文章已经收录在 Github.com/niumoo/JavaNotes ,欢迎Star和指教。更有一线大厂面试点,Java程序员需要掌握的核心知识等文章,也整理了很多我的文字,欢迎 Star 和完善,希望我们一起变得优秀。