上一篇文章介绍了 HashMap 源码,反响不错,也有很多同学发表了自己的观点,这次又来了,这次是 ConcurrentHashMap 了,作为线程安全的HashMap ,它的使用频率也是很高。那么它的存储结构和实现原理是怎么样的呢?
1. ConcurrentHashMap 1.7
1. 存储结构
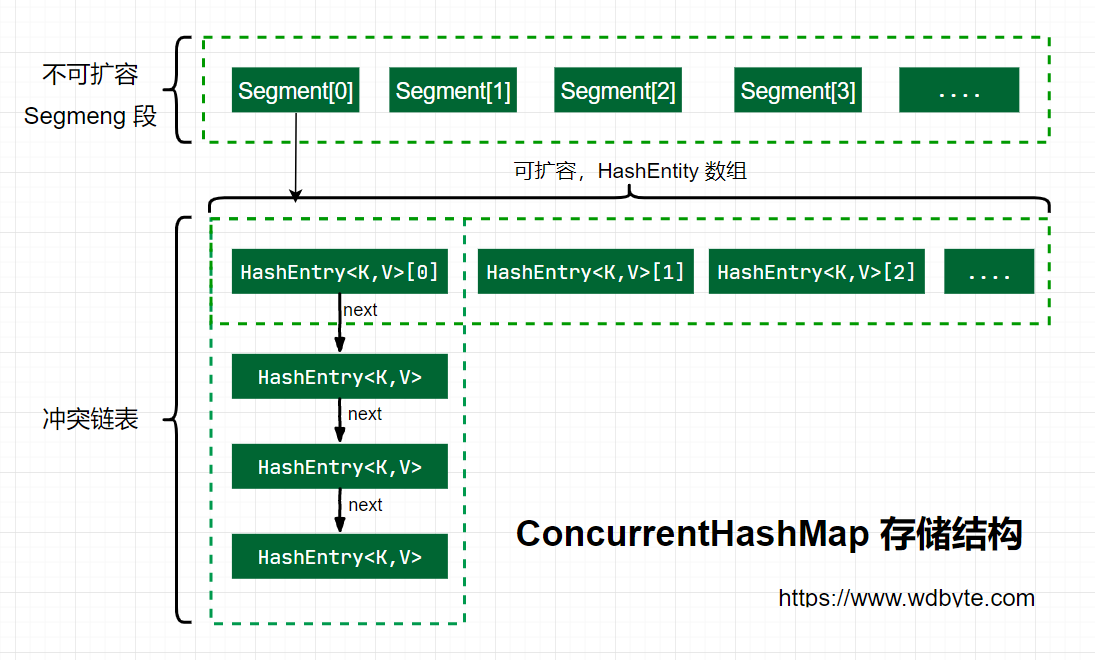
Java 7 中 ConcurrentHashMap 的存储结构如上图,ConcurrnetHashMap 由很多个 Segment 组合,而每一个 Segment 是一个类似于 HashMap 的结构,所以每一个 HashMap 的内部可以进行扩容。但是 Segment 的个数一旦初始化就不能改变,默认 Segment 的个数是 16 个,你也可以认为 ConcurrentHashMap 默认支持最多 16 个线程并发。
2. 初始化
通过 ConcurrentHashMap 的无参构造探寻 ConcurrentHashMap 的初始化流程。
/**
* Creates a new, empty map with a default initial capacity (16),
* load factor (0.75) and concurrencyLevel (16).
*/
public ConcurrentHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
无参构造中调用了有参构造,传入了三个参数的默认值,他们的值是。
/**
* 默认初始化容量
*/
static final int DEFAULT_INITIAL_CAPACITY = 16;
/**
* 默认负载因子
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 默认并发级别
*/
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
接着看下这个有参构造函数的内部实现逻辑。
@SuppressWarnings("unchecked")
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {
// 参数校验
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
// 校验并发级别大小,大于 1<<16,重置为 65536
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
// 2的多少次方
int sshift = 0;
int ssize = 1;
// 这个循环可以找到 concurrencyLevel 之上最近的 2的次方值
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
// 记录段偏移量
this.segmentShift = 32 - sshift;
// 记录段掩码
this.segmentMask = ssize - 1;
// 设置容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// c = 容量 / ssize ,默认 16 / 16 = 1,这里是计算每个 Segment 中的类似于 HashMap 的容量
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
//Segment 中的类似于 HashMap 的容量至少是2或者2的倍数
while (cap < c)
cap <<= 1;
// create segments and segments[0]
// 创建 Segment 数组,设置 segments[0]
Segment<K,V> s0 = new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
总结一下在 Java 7 中 ConcurrnetHashMap 的初始化逻辑。
- 必要参数校验。
- 校验并发级别 concurrencyLevel 大小,如果大于最大值,重置为最大值。无惨构造默认值是 16.
- 寻找并发级别 concurrencyLevel 之上最近的 2 的幂次方值,作为初始化容量大小,默认是 16。
- 记录 segmentShift 偏移量,这个值为【容量 = 2 的N次方】中的 N,在后面 Put 时计算位置时会用到。默认是 32 - sshift = 28.
- 记录 segmentMask,默认是 ssize - 1 = 16 -1 = 15.
- 初始化 segments[0],默认大小为 2,负载因子 0.75,扩容阀值是 2*0.75=1.5,插入第二个值时才会进行扩容。
3. put
接着上面的初始化参数继续查看 put 方法源码。
/**
* Maps the specified key to the specified value in this table.
* Neither the key nor the value can be null.
*
* <p> The value can be retrieved by calling the <tt>get</tt> method
* with a key that is equal to the original key.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>
* @throws NullPointerException if the specified key or value is null
*/
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
// hash 值无符号右移 28位(初始化时获得),然后与 segmentMask=15 做与运算
// 其实也就是把高4位与segmentMask(1111)做与运算
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
// 如果查找到的 Segment 为空,初始化
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
/**
* Returns the segment for the given index, creating it and
* recording in segment table (via CAS) if not already present.
*
* @param k the index
* @return the segment
*/
@SuppressWarnings("unchecked")
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
// 判断 u 位置的 Segment 是否为null
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
// 获取0号 segment 里的 HashEntry<K,V> 初始化长度
int cap = proto.table.length;
// 获取0号 segment 里的 hash 表里的扩容负载因子,所有的 segment 的 loadFactor 是相同的
float lf = proto.loadFactor;
// 计算扩容阀值
int threshold = (int)(cap * lf);
// 创建一个 cap 容量的 HashEntry 数组
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { // recheck
// 再次检查 u 位置的 Segment 是否为null,因为这时可能有其他线程进行了操作
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
// 自旋检查 u 位置的 Segment 是否为null
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
// 使用CAS 赋值,只会成功一次
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
上面的源码分析了 ConcurrentHashMap 在 put 一个数据时的处理流程,下面梳理下具体流程。
-
计算要 put 的 key 的位置,获取指定位置的 Segment。
-
如果指定位置的 Segment 为空,则初始化这个 Segment.
初始化 Segment 流程:
- 检查计算得到的位置的 Segment 是否为null.
- 为 null 继续初始化,使用 Segment[0] 的容量和负载因子创建一个 HashEntry 数组。
- 再次检查计算得到的指定位置的 Segment 是否为null.
- 使用创建的 HashEntry 数组初始化这个 Segment.
- 自旋判断计算得到的指定位置的 Segment 是否为null,使用 CAS 在这个位置赋值为 Segment.
-
Segment.put 插入 key,value 值。
上面探究了获取 Segment 段和初始化 Segment 段的操作。最后一行的 Segment 的 put 方法还没有查看,继续分析。
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 获取 ReentrantLock 独占锁,获取不到,scanAndLockForPut 获取。
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
// 计算要put的数据位置
int index = (tab.length - 1) & hash;
// CAS 获取 index 坐标的值
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
// 检查是否 key 已经存在,如果存在,则遍历链表寻找位置,找到后替换 value
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
// first 有值没说明 index 位置已经有值了,有冲突,链表头插法。
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
// 容量大于扩容阀值,小于最大容量,进行扩容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
// index 位置赋值 node,node 可能是一个元素,也可能是一个链表的表头
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
由于 Segment 继承了 ReentrantLock,所以 Segment 内部可以很方便的获取锁,put 流程就用到了这个功能。
-
tryLock() 获取锁,获取不到使用
scanAndLockForPut方法继续获取。 -
计算 put 的数据要放入的 index 位置,然后获取这个位置上的 HashEntry 。
-
遍历 put 新元素,为什么要遍历?因为这里获取的 HashEntry 可能是一个空元素,也可能是链表已存在,所以要区别对待。
如果这个位置上的 HashEntry 不存在:
- 如果当前容量大于扩容阀值,小于最大容量,进行扩容。
- 直接头插法插入。
如果这个位置上的 HashEntry 存在:
- 判断链表当前元素 Key 和 hash 值是否和要 put 的 key 和 hash 值一致。一致则替换值
- 不一致,获取链表下一个节点,直到发现相同进行值替换,或者链表表里完毕没有相同的。
- 如果当前容量大于扩容阀值,小于最大容量,进行扩容。
- 直接链表头插法插入。
-
如果要插入的位置之前已经存在,替换后返回旧值,否则返回 null.
这里面的第一步中的 scanAndLockForPut 操作这里没有介绍,这个方法做的操作就是不断的自旋 tryLock() 获取锁。当自旋次数大于指定次数时,使用 lock() 阻塞获取锁。在自旋时顺表获取下 hash 位置的 HashEntry。
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
// 自旋获取锁
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
}
else if (++retries > MAX_SCAN_RETRIES) {
// 自旋达到指定次数后,阻塞等到只到获取到锁
lock();
break;
}
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
4. 扩容 rehash
ConcurrentHashMap 的扩容只会扩容到原来的两倍。老数组里的数据移动到新的数组时,位置要么不变,要么变为 index+ oldSize,参数里的 node 会在扩容之后使用链表头插法插入到指定位置。
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
// 老容量
int oldCapacity = oldTable.length;
// 新容量,扩大两倍
int newCapacity = oldCapacity << 1;
// 新的扩容阀值
threshold = (int)(newCapacity * loadFactor);
// 创建新的数组
HashEntry<K,V>[] newTable = (HashEntry<K,V>[]) new HashEntry[newCapacity];
// 新的掩码,默认2扩容后是4,-1是3,二进制就是11。
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++) {
// 遍历老数组
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
// 计算新的位置,新的位置只可能是不便或者是老的位置+老的容量。
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
// 如果当前位置还不是链表,只是一个元素,直接赋值
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
// 如果是链表了
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
// 新的位置只可能是不便或者是老的位置+老的容量。
// 遍历结束后,lastRun 后面的元素位置都是相同的
for (HashEntry<K,V> last = next; last != null; last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
// ,lastRun 后面的元素位置都是相同的,直接作为链表赋值到新位置。
newTable[lastIdx] = lastRun;
// Clone remaining nodes
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
// 遍历剩余元素,头插法到指定 k 位置。
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
// 头插法插入新的节点
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}
有些同学可能会对最后的两个 for 循环有疑惑,这里第一个 for 是为了寻找这样一个节点,这个节点后面的所有 next 节点的新位置都是相同的。然后把这个作为一个链表赋值到新位置。第二个 for 循环是为了把剩余的元素通过头插法插入到指定位置链表。这样实现的原因可能是基于概率统计,有深入研究的同学可以发表下意见。
5. get
到这里就很简单了,get 方法只需要两步即可。
- 计算得到 key 的存放位置。
- 遍历指定位置查找相同 key 的 value 值。
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// 计算得到 key 的存放位置
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
// 如果是链表,遍历查找到相同 key 的 value。
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
2. ConcurrentHashMap 1.8
1. 存储结构
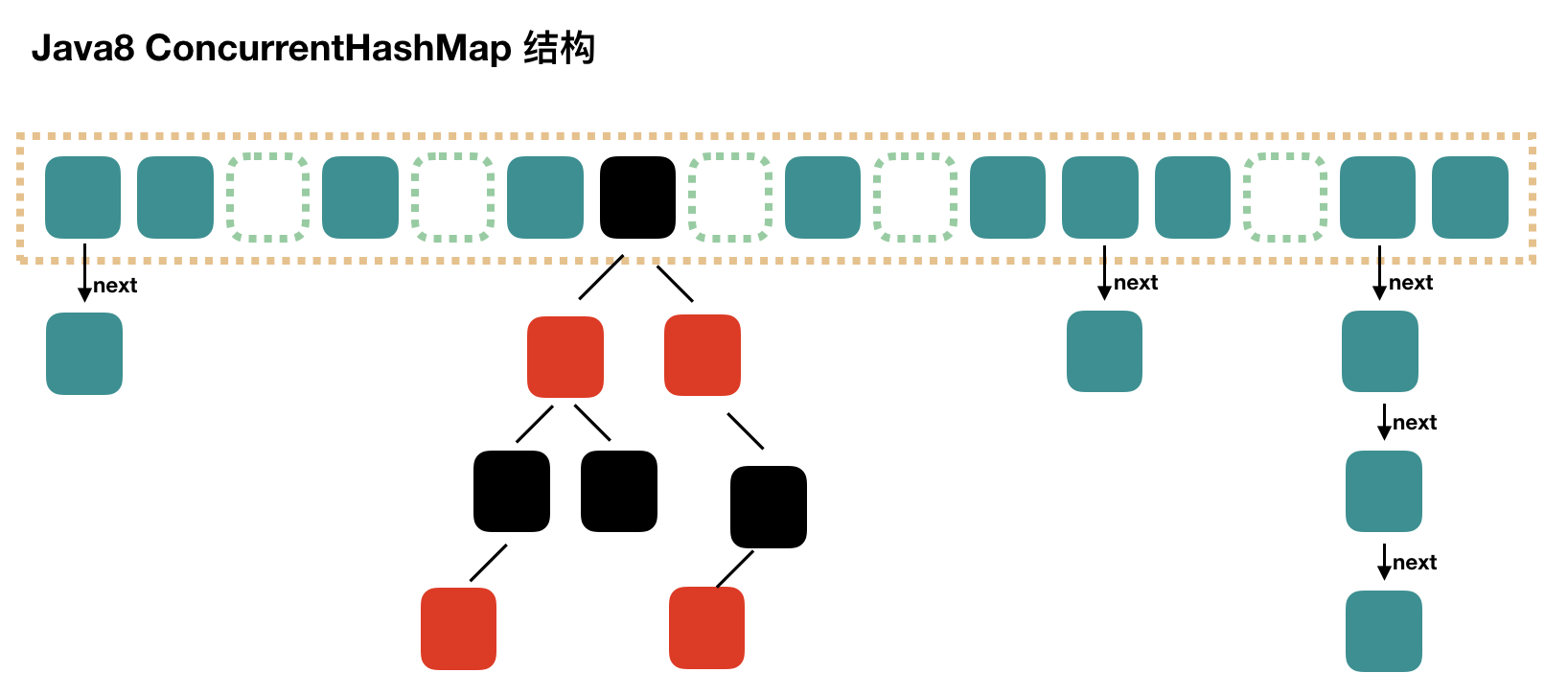
可以发现 Java8 的 ConcurrentHashMap 相对于 Java7 来说变化比较大,不再是之前的 Segment 数组 + HashEntry 数组 + 链表,而是 Node 数组 + 链表 / 红黑树。当冲突链表达到一定长度时,链表会转换成红黑树。
2. 初始化 initTable
/**
* Initializes table, using the size recorded in sizeCtl.
*/
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
// 如果 sizeCtl < 0 ,说明另外的线程执行CAS 成功,正在进行初始化。
if ((sc = sizeCtl) < 0)
// 让出 CPU 使用权
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
从源码中可以发现 ConcurrentHashMap 的初始化是通过自旋和 CAS 操作完成的。里面需要注意的是变量 sizeCtl ,它的值决定着当前的初始化状态。
- -1 说明正在初始化
- -N 说明有N-1个线程正在进行扩容
- 表示 table 初始化大小,如果 table 没有初始化
- 表示 table 容量,如果 table 已经初始化。
3. put
直接过一遍 put 源码。
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
// key 和 value 不能为空
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
// f = 目标位置元素
Node<K,V> f; int n, i, fh;// fh 后面存放目标位置的元素 hash 值
if (tab == null || (n = tab.length) == 0)
// 数组桶为空,初始化数组桶(自旋+CAS)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 桶内为空,CAS 放入,不加锁,成功了就直接 break 跳出
if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 使用 synchronized 加锁加入节点
synchronized (f) {
if (tabAt(tab, i) == f) {
// 说明是链表
if (fh >= 0) {
binCount = 1;
// 循环加入新的或者覆盖节点
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
// 红黑树
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
-
根据 key 计算出 hashcode 。
-
判断是否需要进行初始化。
-
即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
-
如果当前位置的
hashcode == MOVED == -1,则需要进行扩容。 -
如果都不满足,则利用 synchronized 锁写入数据。
-
如果数量大于
TREEIFY_THRESHOLD则要转换为红黑树。
4. get
get 流程比较简单,直接过一遍源码。
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// key 所在的 hash 位置
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// 如果指定位置元素存在,头结点hash值相同
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
// key hash 值相等,key值相同,直接返回元素 value
return e.val;
}
else if (eh < 0)
// 头结点hash值小于0,说明正在扩容或者是红黑树,find查找
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
// 是链表,遍历查找
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
总结一下 get 过程:
- 根据 hash 值计算位置。
- 查找到指定位置,如果头节点就是要找的,直接返回它的 value.
- 如果头节点 hash 值小于 0 ,说明正在扩容或者是红黑树,查找之。
- 如果是链表,遍历查找之。
总结:
总的来说 ConcruuentHashMap 在 Java8 中相对于 Java7 来说变化还是挺大的,
3. 总结
Java7 中 ConcruuentHashMap 使用的分段锁,也就是每一个 Segment 上同时只有一个线程可以操作,每一个 Segment 都是一个类似 HashMap 数组的结构,它可以扩容,它的冲突会转化为链表。但是 Segment 的个数一旦初始化就不能改变。
Java8 中的 ConcruuentHashMap 使用的 Synchronized 锁加 CAS 的机制。结构也由 Java7 中的 Segment 数组 + HashEntry 数组 + 链表 进化成了 Node 数组 + 链表 / 红黑树,Node 是类似于一个 HashEntry 的结构。它的冲突再达到一定大小时会转化成红黑树,在冲突小于一定数量时又退回链表。
有些同学可能对 Synchronized 的性能存在疑问,其实 Synchronized 锁自从引入锁升级策略后,性能不再是问题,有兴趣的同学可以自己了解下 Synchronized 的锁升级。