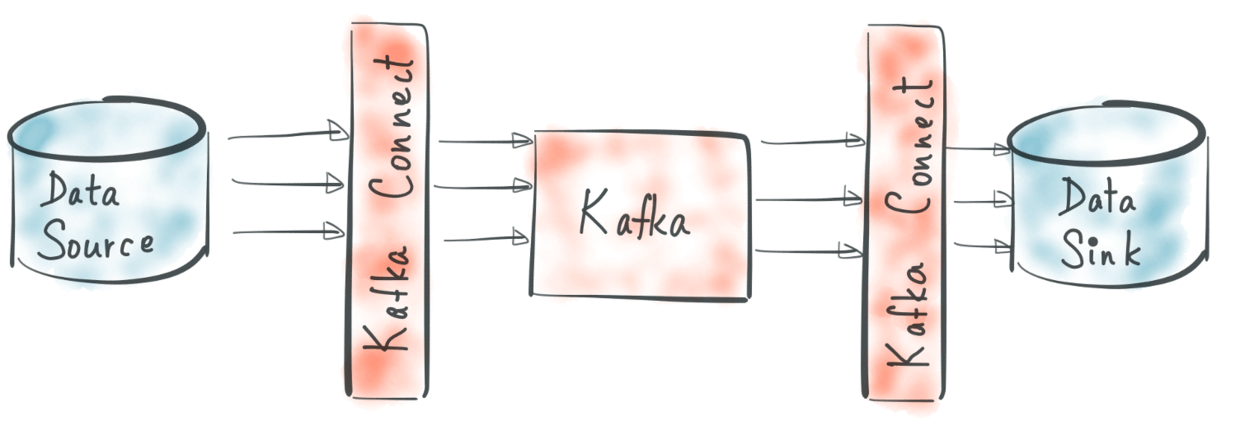
Kafka 来源
Kafka的前身是由LinkedIn开源的一款产品,2011年初开始开源,加入了 Apache 基金会,2012年从 Apache Incubator 毕业变成了 Apache 顶级开源项目。同时LinkedIn还有许多著名的开源产品。如:
- 分布式数据同步系统
Databus - 高性能计算引擎
Cubert - Java异步处理框架
ParSeq Kafka流处理平台
Kafka 介绍
Kafka 用于构建实时数据管道和流应用程序。它具有水平可扩展性,容错性,快速性,并在数千家公司的生产环境中运行。
从官方我们可以知道ApacheKafka是一个分布式流媒体平台。这到底是什么意思呢?
流媒体平台有三个关键功能:
- 发布和订阅记录数据流,类似于消息队列或企业消息传递系统。
- 有容错能力的可以持久化的存储数据流。
- 记录发生时可以进行流处理。
Kafka 通常用于两大类应用:
- 构建可在系统或应用程序之间可靠获取数据的实时流数据管道
- 构建转换或响应数据流的实时流处理
Kafka 基本概念
- Producer - 消息和数据的生产者,向 Kafka 的一个 Topic 发布消息的进程/代码/服务。
- **Consumer **- 消息和数据的消费者,订阅数据(Topic)并且处理其发布的消息的进程/代码/服务。
- Consumer Group - 逻辑概念,对于同一个 Topic,会广播不同的 Group,一个Group中,只有一个consumer 可以消费该消息。
- Broker - 物理概念,Kafka 集群中的每个 Kafka 节点。
- Topic - 逻辑概念,Kafka消息的类别,对数据进行区分,隔离。
- Partition - 物理概念,分片,Kafka 下数据存储的基本单元,一个 Topic 数据,会被分散存储到多个Partition,每一个Partition是有序的。
- **Replication **- 副本,同一个 Partition 可能会有多个 Replica ,多个 Replica 之间数据是一样的。
- Replication Leader - 一个 Partition 的多个 Replica 上,需要一个 Leade r负责该 Partition 上与 Produce 和 Consumer 交互
- ReplicaManager - 负责管理当前的 broker 所有分区和副本的信息,处理 KafkaController 发起的一些请求,副本状态的切换,添加/读取消息等。
概念的延伸
Partition
- 每一个Topic被切分为多个Partitions
- 消费者数据要小于等于Partition的数量
- Broker Group中的每一个Broker保存Topic的一个或多个Partitions
- Consumer Group中的仅有一个Consumer读取Topic的一个或多个Partions,并且是唯一的Consumer。
Replication
- 当集群中有Broker挂掉的时候,系统可以主动的使用Replicas提供服务。
- 系统默认设置每一个Topic的Replication的系数为1,可以在创建Topic的时候单独设置。
Replication特点
- Replication的基本单位是Topic的Partition。
- 所有的读和写都从Leader进,Followers只是作为备份。
- Follower必须能够及时的复制Leader的数据
- 增加容错性与可扩展性。
Kafka 消息结构
在 Kafka2.0 中的消息结构如下(整理自官网)。
baseOffset: int64 - 用于记录Kafka这个消息所处的偏移位置 batchLength: int32 - 用于记录整个消息的长度 partitionLeaderEpoch: int32 magic: int8 (current magic value is 2) - 一个固定值,用于快速判断是否是Kafka消息 crc: int32 - 用于校验信息的完整性 attributes: int16 - 当前消息的一些属性
bit 0~2:
0: no compression 1: gzip 2: snappy 3: lz4
bit 3: timestampType bit 4: isTransactional (0 means not transactional) bit 5: isControlBatch (0 means not a control batch) bit 6~15: unused
lastOffsetDelta: int32 firstTimestamp : int64 maxTimestamp: int64 producerId: int64 producerEpoch: int16 baseSequence: int32 records:
length: varint attributes: int8
bit 0~7: unused
timestampDelta: varint offsetDelta: varint keyLength: varint key: byte[] valueLen: varint value: byte[] Headers => [Header]
headerKeyLength: varint headerKey: String headerValueLength: varint Value: byte[]
关于消息结构的一些释义。
- Offset -用于记录Kafka这个消息所处的偏移位置
- Length - 用于记录整个消息的长度
- CRC32 - 用于校验信息的完整性
- Magic - 一个固定值,用于快速判断是否是Kafka消息
- Attributes - 当前消息的一些属性
- Timestamp - 消息的时间戳
- Key Length - key的长度
- Key - Key的具体值
- Value Length - 值的长度
- Value - 具体的消息值
Kafka 优点
- 分布式 - Kafka是分布式的,多分区,多副本的和多订阅者的,基于Zookeeper调度。
- 持久性和扩展性 - Kafka使用分布式提交日志,这意味着消息会尽可能快地保留在磁盘上,因此它是持久的。同时具有一定的容错性,Kafka支持在线的水平扩展,消息的自平衡。
- 高性能 - Kafka对于发布和订阅消息都具有高吞吐量。 即使存储了许多TB的消息,它也保持稳定的性能。且延迟低,适用高并发。时间复杂的为o(1)。
Kafka 应用
- 用于聚合分布式应用程序中的消息。进行操作监控。
- 用于跨组织的从多个服务收集日志,然后提供给多个服务器,解决日志聚合问题。
- 用于流处理,如Storm和Spark Streaming,从kafka中读取数据,然后处理在写入kafka供应用使用。
Kafka 安装
安装 Jdk
具体步骤此处不说。
安装 Kafka
直接官方网站下载对应系统的版本解压即可。
由于Kafka对于windows和Unix平台的控制脚本是不同的,因此如果是windows平台,要使用bin\windows\而不是bin/,并将脚本扩展名更改为.bat。以下命令是基于Unix平台的使用。
# 解压
tar -xzf kafka_2.11-2.0.0.tgz
# 启动Zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
# 启动Kafka
bin/kafka-server-start.sh config/server.properties
# 或者后台启动
bin/kafka-server-start.sh config/server.properties &
让我们创建一个名为“test”的主题,它只包含一个分区,只有一个副本:
`> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
如果我们运行list topic命令,我们现在可以看到该主题:
`> bin/kafka-topics.sh --list --zookeeper localhost:2181 test
或者,您也可以将代理配置为在发布不存在的主题时自动创建主题,而不是手动创建主题。
查看Topic的信息
./kafka-topics.sh --describe --zookeeper localhost:2181 --topic Hello-Kafka
运行生产者,然后在控制台中键入一些消息以发送到服务器。
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
This is a message
This is another message`
运行消费者,查看收到的消息
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
> This is a message
> This is another message
Kafka 工程实例
POM 依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.1.0</version>
</dependency>
生产者
编写生产者 Java 代码。关于 Properties 中的值的意思描述可以在官方文档中找到 http://kafka.apache.org/ 。下面的生产者向 Kafka 推送了10条消息。
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* <p>
* Kafka生产者,发送10个数据
*
* @Author niujinpeng
* @Date 2018/11/16 15:45
*/
public class MyProducer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.110.132:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<String, String>("test", Integer.toString(i), Integer.toString(i)));
}
producer.close();
}
}
消费者
编写消费者 Java 代码。
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
/**
* <p>
* Kafka消费者
*
* @Author niujinpeng
* @Date 2018/11/19 15:01
*/
public class MyConsumer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.110.132:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("test"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
}
可以在控制台看到成功运行后的输出,由 offset 可以看到已经消费了10条消息。
INFO | Kafka version : 2.0.0
INFO | Kafka commitId : 3402a8361b734732
INFO | Cluster ID: 0Xrk5M1CSJet0m1ut3zbiw
INFO | [Consumer clientId=consumer-1, groupId=test] Discovered group coordinator 192.168.110.132:9092 (id: 2147483647 rack: null)
INFO | [Consumer clientId=consumer-1, groupId=test] Revoking previously assigned partitions []
INFO | [Consumer clientId=consumer-1, groupId=test] (Re-)joining group
INFO | [Consumer clientId=consumer-1, groupId=test] Successfully joined group with generation 4
INFO | [Consumer clientId=consumer-1, groupId=test] Setting newly assigned partitions [test-0]
offset = 38, key = 0, value = 0
offset = 39, key = 1, value = 1
offset = 40, key = 2, value = 2
offset = 41, key = 3, value = 3
offset = 42, key = 4, value = 4
offset = 43, key = 5, value = 5
offset = 44, key = 6, value = 6
offset = 45, key = 7, value = 7
offset = 46, key = 8, value = 8
offset = 47, key = 9, value = 9
问题
如果java.net.InetAddress.getCanonicalHostName 取到的是主机名。需要修改 Kafka 的配置文件。
vim server.properties
# x.x.x.x是服务器IP
advertised.listeners=PLAINTEXT://x.x.x.x:9092